CGNAT Logs: An Idea
In the previous post, we established that CGNAT logs are not observability data. They are not metrics. They are legal artifacts generated at absurd scale.
Once you accept that, the design goal changes.
The goal is no longer “search everything instantly.”
The goal is “retain everything cheaply and answer specific questions reliably.”
What follows is not theoretical. This system already exists. It has been built, tested, and validated on simulated CGNAT data. It works because it respects the shape of the problem.
This is how to treat CGNAT logs properly.
Step 1: Stop thinking in indices, start thinking in slices
CGNAT data is time series data, but not in the way metrics are.
Each record is immutable.
Each record belongs to a precise time window.
Most records are never touched again.
That makes time slicing the natural primitive.
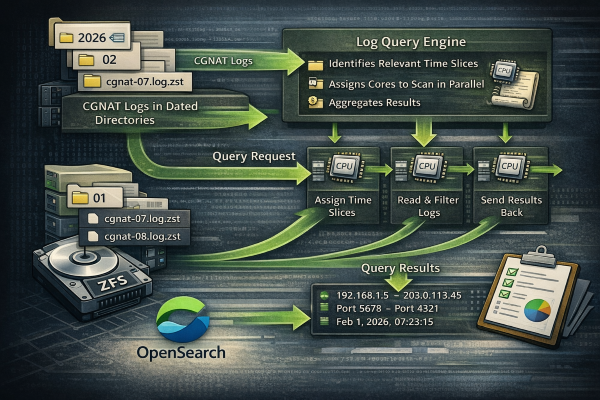
Logs are written to disk in fixed time slices, one hour being a common and practical choice. The exact slice size is adjustable based on workload, flow rate, and operational preferences.
Each slice is a flat file.
Append only.
No indexing.
No mutation.
Slices are stored in date-based directory structures so navigation is deterministic and cheap.
For example:
Nothing clever. Nothing fragile.
Step 2: Disk is the system of record
These slices live on disk. Preferably boring disk.
ZFS mirrors are ideal here because they give you exactly what CGNAT needs:
-
predictable write behavior
-
data integrity
-
cheap redundancy
-
simple replication
This data can be:
-
mirrored locally
-
sharded across hosts
-
fully replicated to secondary hosts
The system does not care. Files are files.
There is no cluster state. No quorum. No heap. No leader election.
Disk holds the truth.
Step 3: Searching is a compute problem, not a storage problem
This is the critical mental shift.
Instead of pre-indexing everything, you defer computation until the moment you actually need an answer.
When a query is required, a dedicated program is invoked.
That program does exactly three things:
-
Identifies which time slices are relevant
-
Assigns slices to worker processes
-
Scans them in parallel
You tell it how many cores to use.
Eight cores will work.
Forty cores will work faster.
There is no timeout because nothing is waiting on heap or coordination locks.
This is embarrassingly parallel work, and the system treats it that way.
If the data exists on multiple hosts, the program is topology-aware and enlists those hosts as well. Their CPUs become part of the query.
The logs stay where they are. The compute goes to the data.
Step 4: Deterministic performance instead of fragile performance
This approach has a property most search stacks do not.
Performance is linear and predictable.
-
More cores means faster completion
-
More hosts means faster completion
-
More data means proportionally more time
Nothing falls off a cliff. Nothing silently degrades.
There is no heap exhaustion.
There are no long GC pauses.
There is no cluster instability.
The worst case is simply “this takes longer.”
That is an acceptable failure mode.
Step 5: Output is a product, not an afterthought
Once the scan completes, the results are materialized.
The output format is selectable:
-
human readable reports
-
structured data
-
CSV
-
JSON
-
custom templates
Optionally, the result set can be written into OpenSearch.
This is the correct role for OpenSearch.
It becomes a secondary system used for:
-
aggregation
-
visualization
-
short term analysis
-
dashboards
OpenSearch never holds the full CGNAT corpus. It holds answers, not raw truth.
Step 6: Preprocessing beats aggregation every time
Monthly reports are where most systems break.
Trying to aggregate a month of CGNAT data directly in OpenSearch will fail, not because OpenSearch is bad, but because the workload is wrong.
This data requires preprocessing.
Your system already supports that.
You can:
-
compute daily rollups
-
compute hourly summaries
-
extract trend metrics
Those summaries are small, stable, and perfect for OpenSearch dashboards.
Raw data stays on disk.
Derived data goes to search.
That separation is the whole game.
Step 7: Why this works
This design succeeds because it aligns with reality.
CGNAT logs are:
-
write once
-
read rarely
-
immutable
-
time bounded
The system treats them exactly that way.
There is no fantasy about “instant search across everything forever.”
There is no pretending this is observability data.
There is no unnecessary indexing tax.
Just files, CPU, and math.
The real takeaway
This is not clever engineering. It is disciplined engineering.
CGNAT logging punishes systems that try to be elegant.
It rewards systems that are boring, parallel, and honest about scale.
Store everything cheaply.
Compute only when needed.
Index only the answers.
That is how you survive CGNAT at rural scale without lighting money on fire.
Part 3 -> If I Were To Build It Today